
Reddit Comment Engagement
“Don’t believe everything you read on the internet” - Abraham Lincoln
Predicting Comment Engagement on Reddit
Ah, Reddit. The place that we all pretend is unfamiliar to us, so that we seem more employable. But how can one possibly resist the front page of the internet, when it has something to offer everyone? Rarepuppers, slavs_squatting, BillyMaysMixtapes; there truly is a subreddit as unique and individual as each one of us.
Everyone loves to browse the posts, but what makes someone stop, take precious (or not so precious) time out of their day, and add their own comment? Can we predict the overall level of comment engagement, based solely on the metadata of the post itself? Of course you can! This would be a useless blog post if you couldn’t (well, more useless I mean).
If you like getting into the weeds, the coding information for this project can be found on my GitHub: github.com/Tucker-Allen/Reddit_Comment_Engagement
You can also find slides from my presentation here.
Data Scraping:
There’s a lot of metadata attached to each post on the Reddit website. Unfortunately, there isn’t a Reddit Data Walmart we can go to, pick up a box of ‘data’, and walk out. But luckily, we do have access to the web-hosted Reddit API (think of it more like an all-you-can-eat Chinese buffet, but it’s out in the middle of the woods, you only have Mapquest directions, and it’s printed on soggy paper so the ink is running).
Using the Reddit Praw (Python Reddit API Wrapper), we can request any number of posts matching any number of criteria, and access the metadata attached to those posts intuitively. Given that knowledge, I constructed a scraper that leverages Praw, hosted on Amazon Web Services, that:
- Scraped the top 500 posts from the front page every 15 minutes.
- Stored 19 features of metadata for each post scraped.
- Output a CSV checkpoint file every 4 hours (in case of an overall crash of the scraper)
- Terminated after 48 hours of run time.
This provided me exactly 96,000 rows of information, each representing a snapshot of a Reddit post at the time it was scraped, with all the metadata I wanted from that post attached. Neat.
Fun Facts:
- 2,876 unique posts made the “top 500” over the 48 hour period scrape
- Each of those posts were created by 2,643 unique authors
- Median Number of comments = 95
- Average Number of Comments = 280
- Maximum Number of Comments = 21,315!
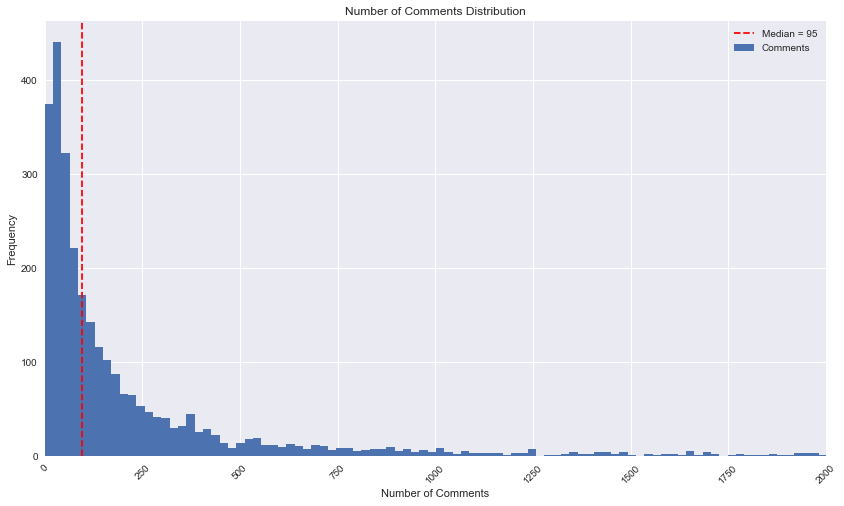
A look at the overall distribution of post domain sources…
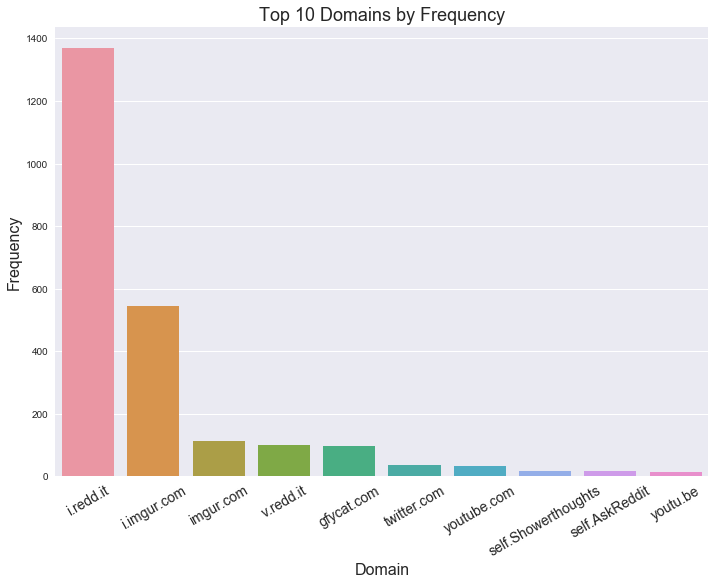
It looks like Reddit and Imgur source domains rule the front page.
A look at the overall distribution of what time of day posts are created…
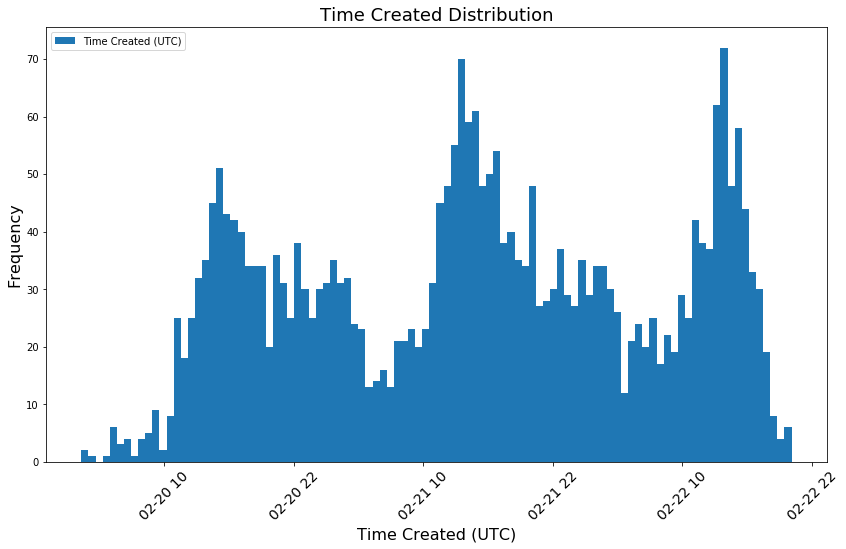
Peaks are noticed at approximately 9am EST, while troughs are at approximately 11pm EST. It appears U.S.-based East Coasters are looking to do anything that doesn’t involve starting the workday.
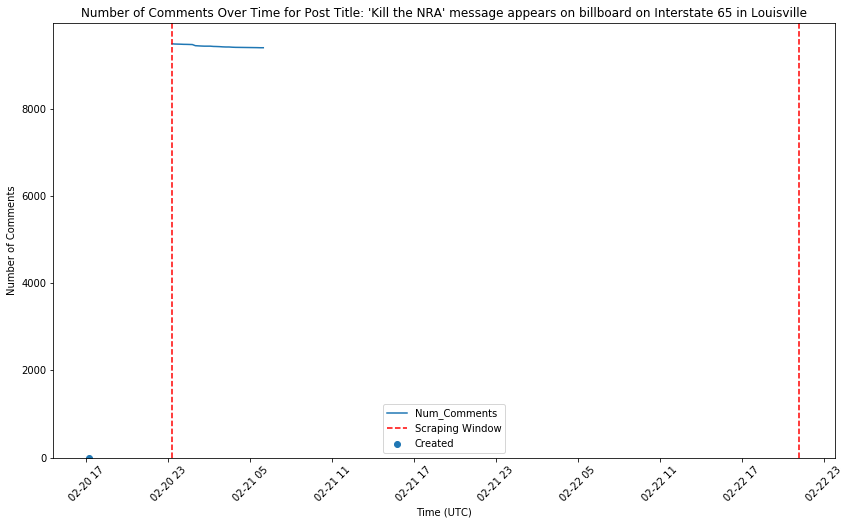
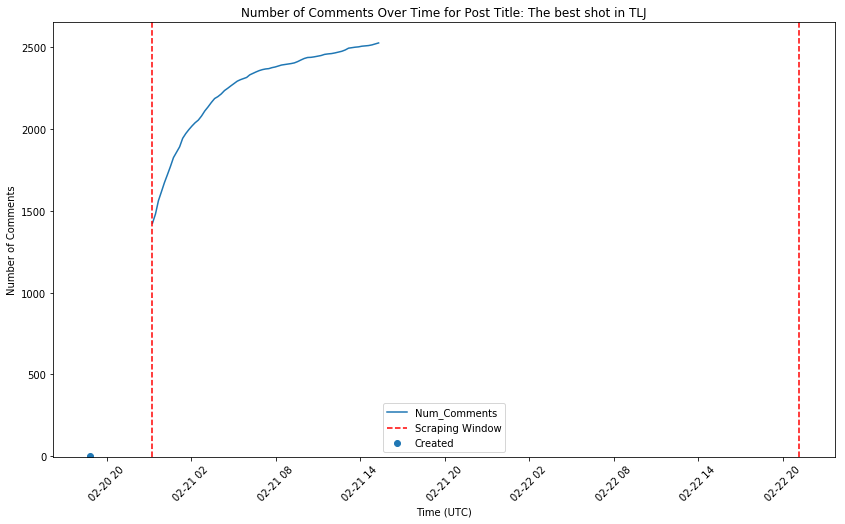
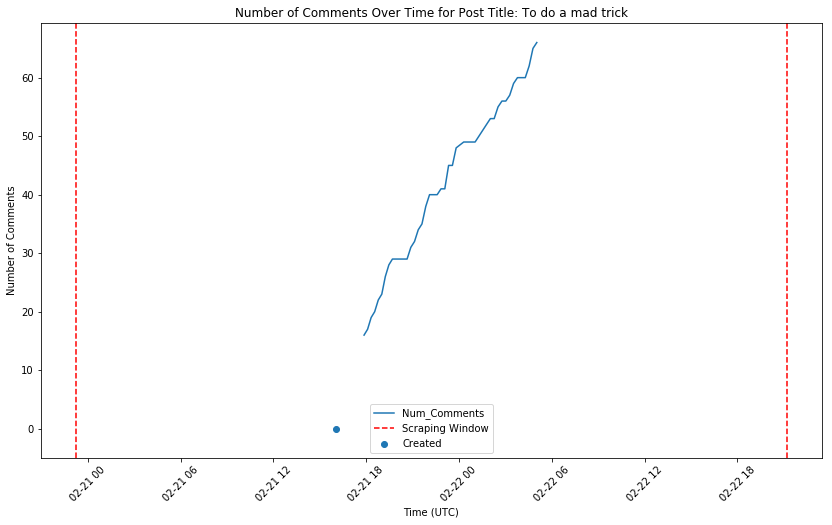
Exploring how the number of comments typically grow over time
There are two things I noticed that are going to introduce some strange noise to our data:
-
Since our scraper only ran for 48 hours, our dataset will include some “young” posts, that have not totally “matured” yet in total comment number.
-
How long a post is allowed by Reddit to occupy a spot in the “Top” section is a bit of a black box. It seems that some posts are terminated more quickly than others, so it may not be based exclusively on an overall duration. Researching that for another day…

The Most important text in determining High/Low comment engagement:
…In the Subreddit Title
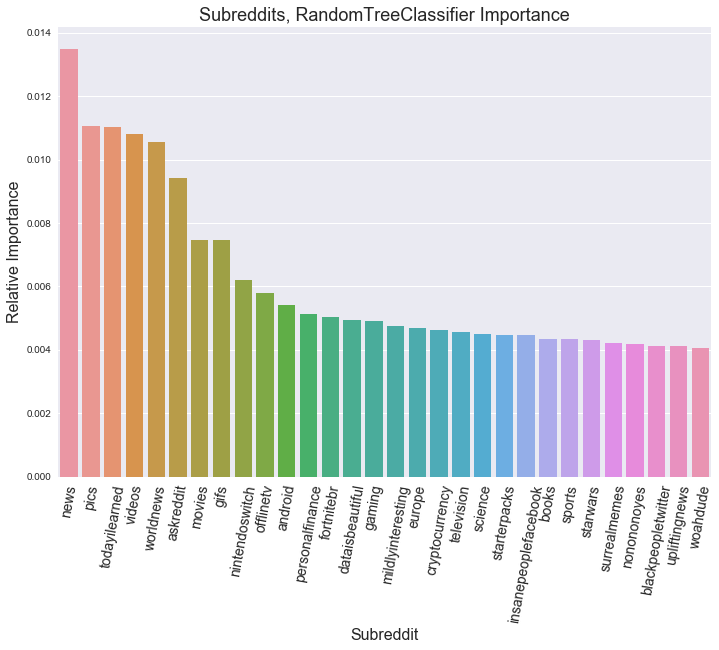
News, TodayILearned, and AskReddit bubbled to the top, which makes sense. A lot of people will probably feel inclined to add there 2 cents to such topics.
…In the Post Title
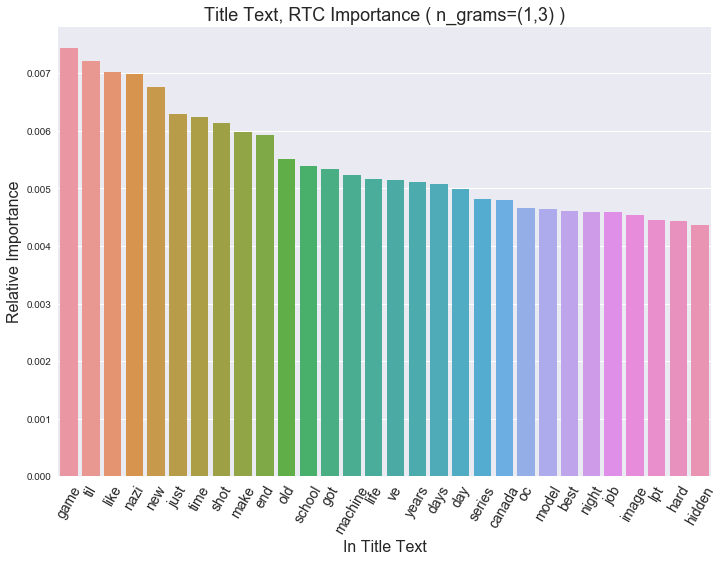
Hm, pretty erratic. Let’s see if we can tease out some topics by increasing n_grams…
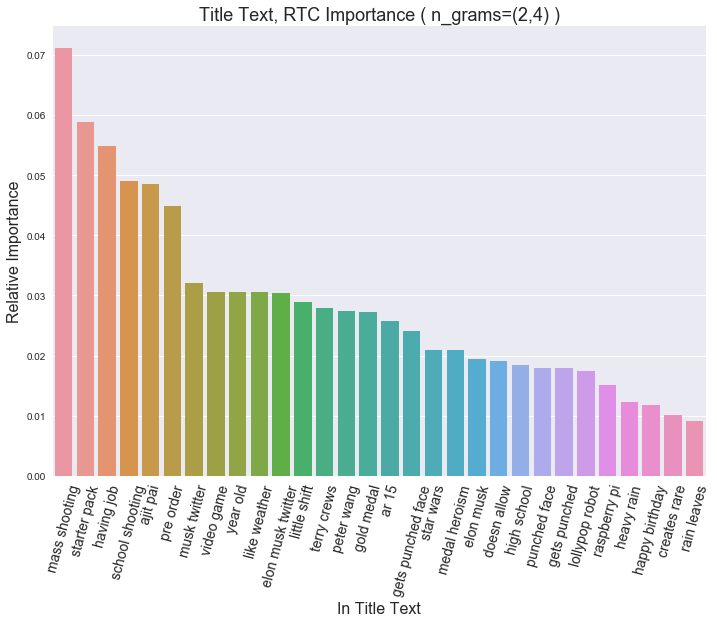
…Look at that! “mass shooting” and “school shooting”, America’s favorite pastimes. Oh, and Elon Musk of course.
…In the domain name
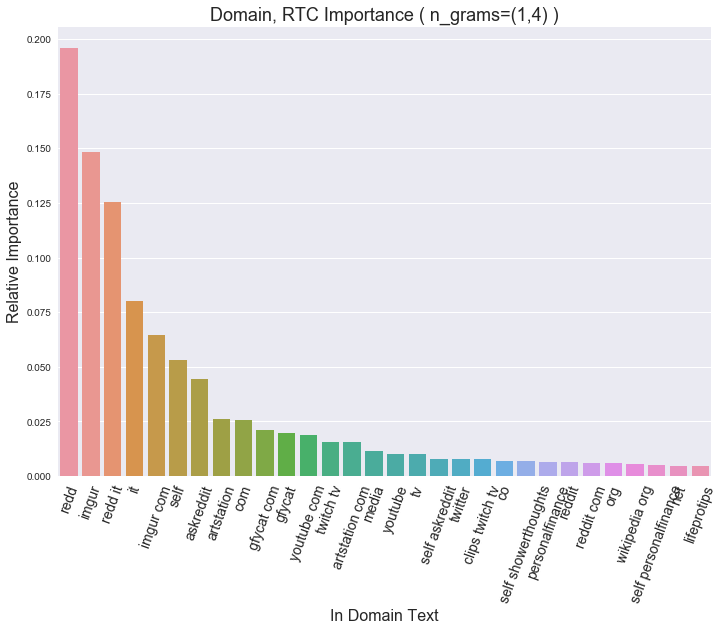
Reddit and Imgur running the show here again, no surprises.
…Within the text of the post (if any was included, usually there is not)
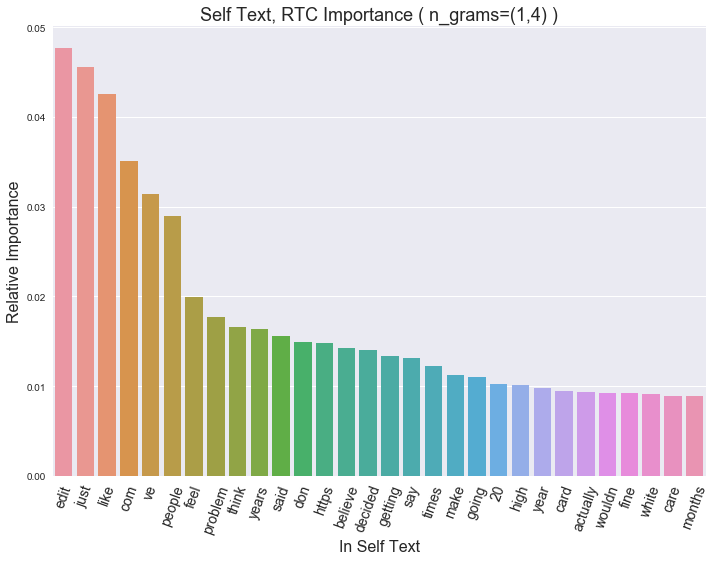
It looks like a lot of ‘feeling’ words like ‘feel’, ‘problem’ and ‘care’. Those topics that stir emotional resonse are probably going to ellicit the most engagement.
Conclusion
There was certainly a lot of noise in our data given the climate at the time of the webscrape (Parkland school shooting). Still, it looks like you can get a lot of comment mileage out of emotionally polarizing topics, or anything about Elon Musk. Stay classy, Reddit.